Description
Welcome to my personal blog!
GitHub Profile: https://github.com/jianxun-p
LinkedIn Profile: https://www.linkedin.com/in/jianxun-pan-210a70321
Email: Steven <contact@shimaodexibao.dpdns.org>
Partial SHA-2 Collision with Prefix/Suffix (oneAPI SYCL)
Link to GitHub Repository: https://github.com/jianxun-p/partial-sha2-collision-with-oneapi
This project searches for a partial collision in SHA-2 outputs: two different inputs that share the same first N bytes of hash output.
Inputs are constrained to this format:
input = prefix || variable_middle(N bytes) || suffix
The implementation uses a Van Oorschot–Wiener (VOW) style collision search with distinguishable points (DPs) and runs in parallel with oneAPI SYCL.
Table of Contents
- Results
- Secure Hash Algorithm 2 (SHA-2) & The Merkle–Damgard Construction
- Van Oorschot–Wiener
- Features
- Repository Layout
- Configuration
- Build
- Run
- Example Collision Condition
- Disclaimer
Results
Here are the results for SHA256 (prefix = 0x00112233 and suffix = 0x33221100):
| Collision Size (N) | K | Device | Hash Count | Duration | Average Hash Speed |
|---|---|---|---|---|---|
| 7 | 2 | AMD R9-9900X CPU | 2,000,114,392 hashes | 32 seconds | 62,503,574 hashes/second |
| 8 | 2 | AMD R9-9900X CPU | 10,000,252,285 hashes | 82 seconds | 121,954,296 hashes/second |
| 9 | 2 | AMD R9-9900X CPU | 26,000,102,890 hashes | 179 seconds | 145,251,971 hashes/second |
| 7 | 2 | Intel Arc B580 GPU | 2,000,114,392 hashes | 2 seconds | 1,000,057,196 hashes/second |
| 8 | 2 | Intel Arc B580 GPU | 10,000,252,285 hashes | 7 seconds | 1,428,607,469 hashes/second |
| 9 | 2 | Intel Arc B580 GPU | 26,000,102,890 hashes | 22 seconds | 1,181,822,858 hashes/second |
Potential Optimizations (CPU)
The number of work-item (THREADS) and BATCH_SIZE can be reduced.
Memory allocation/release is time consuming, which increased duration and average hash speed. The effect is more significant for smaller collision sizes.
Bottleneck: There exists 2 copies of the same data in the memory, and copying between them is unnecessary and time consuming.
The step of reduction with a single thread of CPU can be optimized, other threads are running idle at that time.
Potential Optimizations (GPU)
States are written/updated by device, the host only reads it, using device memory with memcpy to host memory for State may be a better alternative.
Bottleneck: The step of reduction with a single thread of CPU can be optimized, the GPU is running idle at that time.
Secure Hash Algorithm 2 (SHA-2) & The Merkle–Damgard Construction
The SHA-2 is based on the Merkle–Damgard construction.
The Merkle–Damgard construction consists of a compression function, (see function sha2_compression), which needed to be:
- pre-image resistant
- i.e. when given , it is computationally infeasible to find , such that
- second pre-image resistant
- i.e. when given , it is computationally infeasible to find , such that
- collision resistant
- i.e. it is computationally infeasible to find any pairs of such that
- collision resistance implies second pre-image resistance
For a given message , the hash value of a hash function using the Merkle–Damgard construction is , where:
- : intial hash values (i.e. initial vectors), see NIST's publication
- for
Secure Hash Algorithm 2 (SHA-2)
See NIST's publication for details: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.180-4.pdf
Van Oorschot–Wiener
Distinguishable Point (DP) are values such that the first K bytes equal to zero.
Create chains of start_DP -> end_DP (Stage 1).
If two chains have the same end_DP and different start_DP, then these two chains must have merged together at some point.
We backtrack (Stage 2) to find the point where they merge together.
Stage 1: Parallel random walks + DP collision search
Each worker thread:
- Starts from a deterministic seed
- Repeatedly hashes
prefix || middle || suffix - Treats outputs with first
Kbytes equal to zero as a distinguishable point - Stores chains ending at DPs
When two chains hit the same DP key (matching first N bytes), stage 1 returns two chain starts (X, Y) and distances to that DP.
Stage 2: Backtracking to find the actual partial collision
The two chains are aligned by step count and advanced together until the first point where their first N hash bytes match. The corresponding two inputs are reported.
Features
- Supports SHA-2 family variants:
SHA224,SHA256,SHA384,SHA512,SHA512_224,SHA512_256
- Configurable partial-collision size (
Nbytes) - Configurable DP condition (
Kbytes, whereK <= N) - Prefix/suffix constrained input space
- Parallel stage-1 walk on CPU/GPU SYCL device
- Header-only SHA-2 implementation in sha2.hpp
Repository Layout
- main.cpp: VOW search logic, SYCL kernels, collision reporting
- sha2.hpp: Header-only SHA-2 implementations
- Makefile: Build and run targets
Configuration
Edit constants near the top of main.cpp:
hash_type: select SHA-2 variantN: number of leading output bytes that must collideK: DP prefix length in bytes (K <= N)prefix,suffix: fixed bytes around the variableN-byte middleTHREADS: number of parallel walkersBATCH_SIZE: steps per walker before host merge/checkDP_ARRAY_LEN: max DPs stored per thread per batch
Notes
- Larger
Nincreases expected work roughly as for birthday-style partial collisions (in bits: ). - Larger
Kreduces DP frequency; smallerKincreases merge overhead. - Tune
THREADS,BATCH_SIZE, andDP_ARRAY_LENfor your device memory and throughput.
Build
Prerequisites:
- Intel oneAPI DPC++/C++ compiler (
icpx) - oneAPI/SYCL runtime properly configured in shell environment
Option 1: Build with Makefile
The project Makefile compiles to sha2_collision (or sha2_collision.exe on Windows).
Option 2: Direct compile command
icpx -fsycl -O3 -std=c++20 -Wall -Wextra -march=native -o sha2_collision main.cpp
Run
Run the built binary.
Program output includes:
- selected SYCL device
- stage-1 batch progress and hash counts
- detected DP collision
- stage-2 alignment/backtracking logs
- final partial collision inputs and outputs
- total hashes, duration, and hashing speed
Example Collision Condition
If N = 8, success means the first 8 bytes of the two outputs are identical:
hash(input1)[0..7] == hash(input2)[0..7]
with input1 != input2 and both matching the prefix || middle || suffix format.
Disclaimer
This project is for educational and research use (parallel hash search, SYCL programming, and collision-search techniques). Do not use it for unauthorized security testing.
Fetch GitHub Repo Latest Release Info
Link to GitHub Repository: https://github.com/jianxun-p/github-repo-release-info-pulling
About
AI-Agent for pulling GitHub release information with automated browsers and vision models.
This project uses LangGraph along with OpenAI's API (GPT-5.1 model).
It controls the browser to fetch the latest release information of the specified repository (openclaw in the example, see navigate.py) from GitHub.
Development Proccess
Initial Approach
Initial Approach & Visual Challenges Initially, I implemented a bordered selection box on screenshots and prompted a multimodal model to "move the selection box to include the target." The model was provided with the following function-calling tools:
- Translate Box: Moves the box in four directions by fixed increments.
- Zoom Box: Scales the box up or down by fixed increments.
- Interactions: Executes keyboard inputs, clicks, and double-clicks.
This approach yielded no progress. I suspected the model struggled to perceive the thin selection border, but even after switching to a high-contrast red shaded rectangle, performance remained poor.
Introducing ReAct Agentic Loops
Transition to ReAct Agentic Loops To improve reliability, I decomposed the problem into smaller tasks by introducing an agentic loop. The system now constantly monitors the current state to determine if the target is within the box. If the target is not captured, the logic determines the next necessary action (zooming, moving, or inputting text).
While this improved performance—correctly moving toward the target in roughly 50% of cases—the model frequently suffered from "looping," where it moved the box back to previously visited coordinates. Resetting the message history and refining the prompt offered negligible improvements.
Locating the Target First with Divide and Conquer
Divide and Conquer Observing that the model was significantly more accurate at verifying the target's presence than manipulating the tools, I shifted to a "divide and conquer" strategy. I restricted the model’s role solely to locating the target, while the Python backend handles the search logic.
This narrowed focus allows the system to locate targets using a logarithmic search pattern. To mitigate hallucinations, I implemented a "zoom-out" recovery step, allowing the system to backtrack if a false positive is detected. This final iteration has proven to be the most robust.
Generators for Function Calling Tools
Generators for Function Calling Tools To further optimize the codebase, I refactored the function-calling tools to utilize Python generators. This allows for more efficient state management and cleaner code, as the generator can yield control back to the main loop after each action, enabling better handling of asynchronous interactions with the browser and model responses.
It take advantage of the document comments of the functions to automatically generate the tool descriptions for the model, which significantly reduces the amount of tokens used and also makes it easier to maintain the codebase since there is no need to manually update the tool descriptions when the function signatures change.
See tool.py for the implementation of the generators for function-calling tools.
See browser.py for the usage of the generators.
This was significant improvement in readability and maintainability of the code, as well as reducing token usage and improving the overall performance of the agent.
Target Localization Based On Text Recognition
Since LLMs excel at interpreting text, I also implemented an OCR-based approach for target localization. The model extracts text from screenshots and uses function-calling tools to invoke the appropriate Playwright functions. This yielded higher accuracy while reducing token usage and improving speed.
Changing Model to GPT-5.1 and Refactoring with LangGraph
GPT-4.1-mini was used in the initial implementation, but it struggled with hallucinations and had limited context window. After switching to GPT-5.1, the model's performance improved significantly, with more accurate target localization and reduced hallucinations. However, this change cause money cost to increase significantly, so I had to optimize the prompt and reduce token usage.
LangGraph Integration With the introduction of LangGraph, I restructured the codebase to leverage its agentic capabilities. The core logic of the agent remains consistent with the previous iteration, butthe implementation is now more modular and maintainable. LangGraph's framework allows for clearer separation of concerns, making it easier to manage the agent's state and interactions with the environment.
Future Improvements
Need a way to backtrack when the model makes a wrong move, which is inevitable. The current method is to zoom out to the previous state, but it is not ideal since it is not guaranteed that the target would be in the box after zooming out, and it also wastes a lot of tokens and time.
MCP Server for Cover-Letter Generation
Link to GitHub Repository: https://github.com/jianxun-p/cover-letter-generation-mcp
A lot of people uses AI to generate cover letters, but the problem is that they have to copy and paste the job description and their resume to the AI model and produce a PDF, which is time consuming (converting them into LaTeX and compile into PDF) and may have privacy concerns. This project is a simple MCP server that allows users to generate cover letters without having to share their sensitive data with any third-party services. The server is built with Python and FastMCP.
It ensures consistent format and style for all cover letters by leveraging a LaTeX template, making it easier for users to create professional and personalized cover letters for their job applications. The server can be easily deployed on any platform that can run Docker Images.
This MCP server provides prompts for the AI model to generate the content of the cover letter. Functionality for compiling the generated LaTeX into PDF is also provided for the model to use (the model have access to neither the intermediate results nor the final PDF).
Privacy and Security
Your sensitive information such as name, phone number, address, links are not shared with any third-party services (including the model for generating the content of the cover letter), they are only used to fill in the LaTeX template and generate the cover letter.
Financial Management Application (Boom My Wallet)
Link to GitHub Repository: https://github.com/jianxun-p/Boom-My-Wallet
Link to Deployed Application: https://boommywallet.uk.r.appspot.com/
This project is deployed on Google Cloud Platform (GCP) and is a financial management application that allows users to track their expenses.
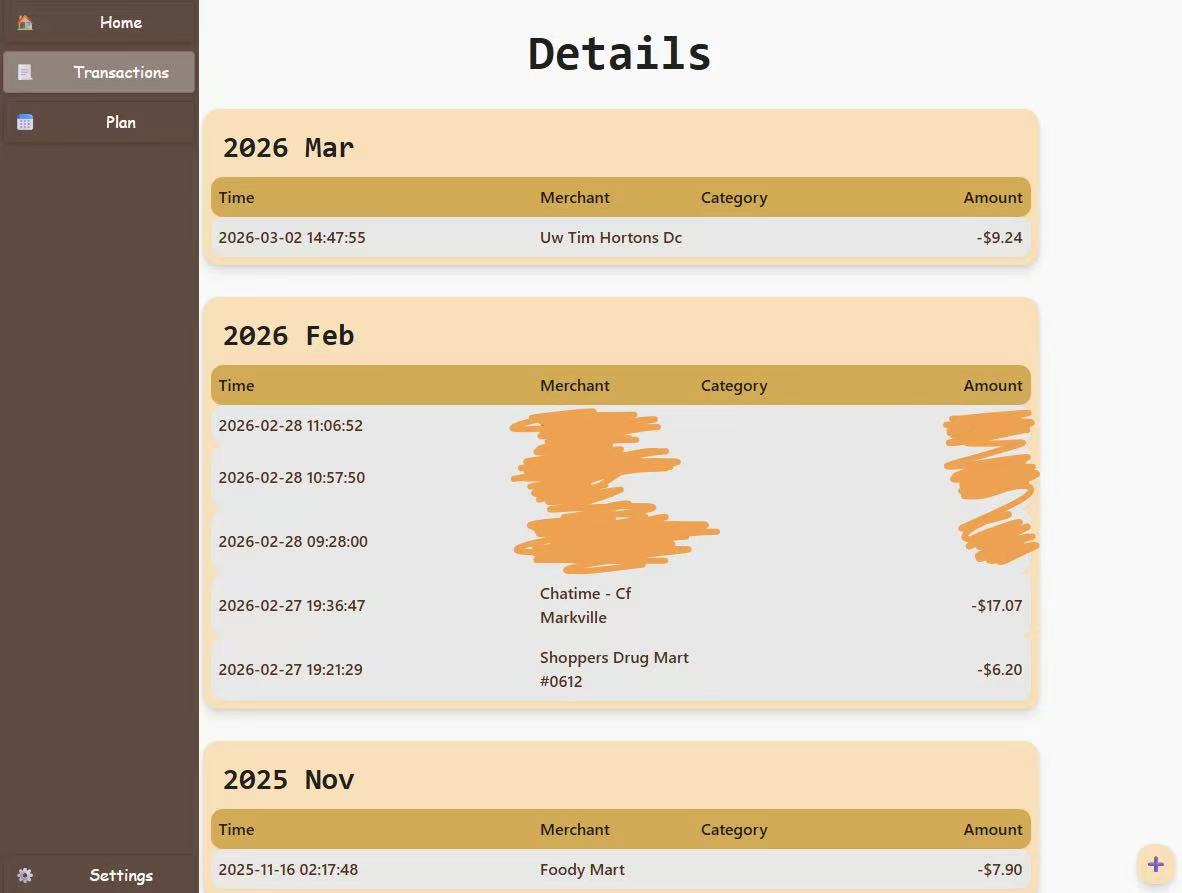
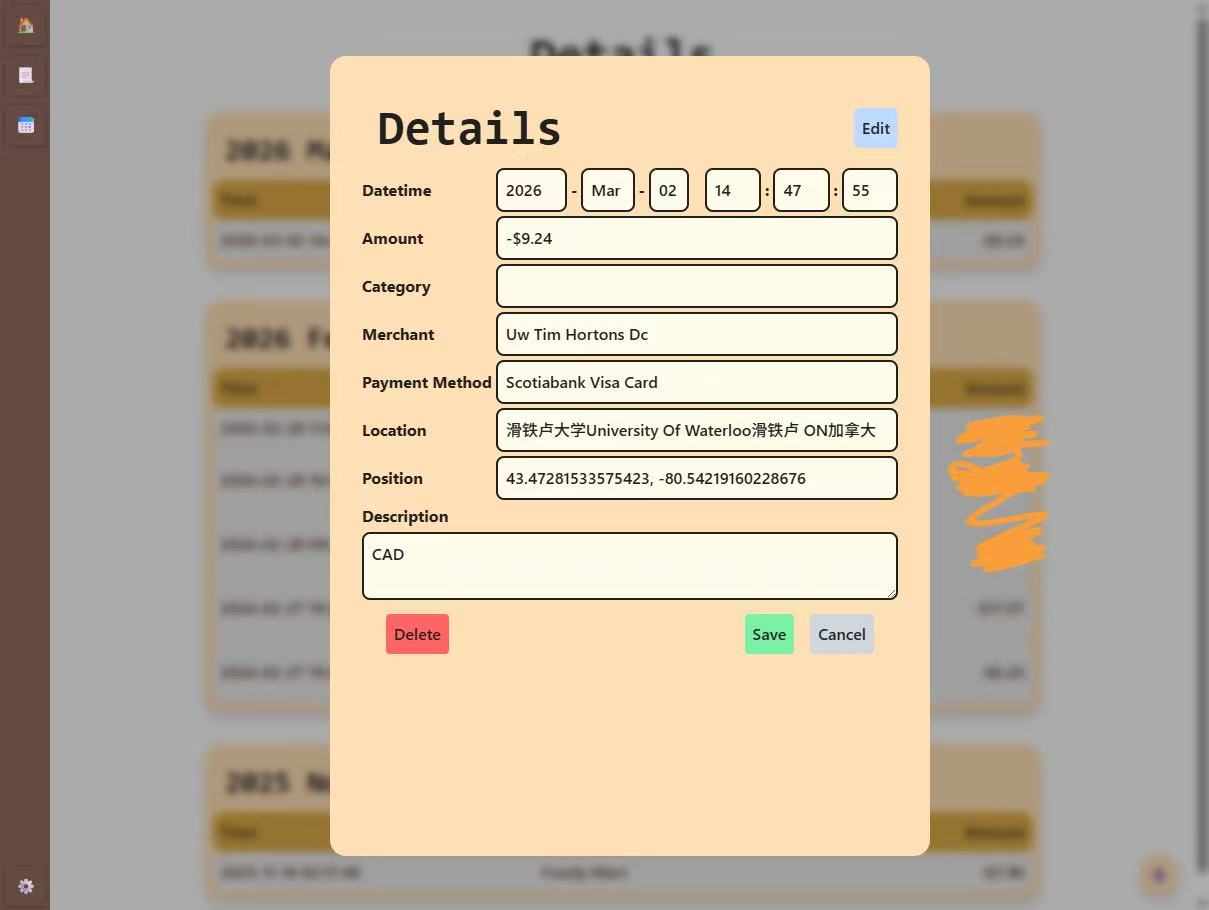
Note: The text is in Chinese because my phone is set to Chinese, but the application supports all languages (including English).
Table of Contents
- Introduction
- Why Another Financial Manager?
- Security
- Data Storage, Ownership and Privacy
- UI and Data Visualization
- Automatic Expense Logging
Why Another Financial Manager?
There are already many financial management applications available in the market, so why did I choose to build another one? The main reason is that many of the existing applications are either too propertary and user does not have , which means that they are not open-source and may have privacy concerns, or they are too complex for the average user to navigate. I wanted to create a simple application targeted for more technical people that allows users to easily track their expenses without having to worry about the security and ownership of their data.
Security
The application is designed with security in mind. By using Google Sheets API, the application does not store any user data on its own servers, which means that there is no risk of data breaches or unauthorized access to user data. Additionally, the application uses OAuth 2.0 with OpenID-Connect for authentication, which ensures that only authorized users can access their financial data.
Access Tokens Storage
Access tokens are hashed with salt and stored in the Firestore database, which adds an additional layer of security to protect user data. This means that even if the database is compromised, the access tokens cannot be easily used to gain unauthorized access to user data.
The first layer of hashing is done with the SHA-256 algorithm, which is a widely used cryptographic hash function that produces a fixed-size output. It is designed to be fast and efficient, making it suitable for hashing large amounts of data. However, it is not designed to be resistant to brute-force attacks, which is why I added a second layer of hashing with scrypt. This output can also be used to check if the access token has been compromised in a data breach by comparing it against a database of known compromised tokens, such as the one provided by Have I Been Pwned.
The second layer of hashing is done with scrypt, which is a password hashing function that incorporates a salt to protect against rainbow table attacks and is designed to be computationally expensive to prevent mass-scale brute-force attacks.
CSRF and XSS Protection
The application also implements protection against Cross-Site Request Forgery (CSRF) and Cross-Site Scripting (XSS) attacks. CSRF protection is implemented by generating a unique token/ID for each user session that is stored in Cookies (SameSite=Strict, Secure=True, HttpOnly=True with a short expiration time). The server then validates the token to ensure that the request is coming from an authenticated user. XSS protection is achieved by not processing any user input on the server side. This means that any user input is treated as plain text and is not executed as code, which helps to prevent XSS attacks. X-Frame-Options is also set to DENY to prevent clickjacking attacks.
Data Storage, Ownership and Privacy
User's financial data is stored in their own Google Drive (a Google Sheet file), which means that users have full control over their data and can easily export it to other applications for further analysis. The application uses Google Sheets API to read and write data to the user's Google Drive, which ensures that the data is stored securely and is easily accessible to the user.
This also means that users are not stuck with the application if they decide to switch to other solutions, they can easily export their data to other applications or even just keep it in their Google Drive for future reference.
UI and Data Visualization
The UI of the application is designed to be simple and intuitive. The main page displays a list of all expenses, and users can easily add new expenses by clicking on the "Add Expense" button. Each expense entry includes the amount, payment type, location, and date of the expense. Users can also edit or delete existing expenses by clicking on the corresponding buttons next to each entry.
It is created with React + TypeScript + Tailwind CSS. Originally, I wanted to use recharts to display the data in a more visual way, but I figured that it was not what I needed, Google Sheets already provides a good way to visualize data, and I can easily export the data to Google Sheets for further analysis. The charts created by Google Sheets are much more customizable.
Automatic Expense Logging
The application exposes an API endpoint that allows users to log expenses automatically by sending a POST request with the expense details in the request body. This feature is particularly useful for users who want to log expenses on the go, such as when they are out shopping or dining at a restaurant. By using this API endpoint, users can quickly and easily log their expenses without having to open the application and manually enter the details.
Apple Shortcuts Integration
The API endpoint can be easily integrated with Apple Shortcuts, which allows users to log expenses automatically when an payment is made through Apple Pay. This integration eliminated the need for users to manually log their expenses, making it even more convenient to keep track of their spending. With this feature, users can simply set up a shortcut that triggers the API endpoint whenever they make a payment with Apple Pay, and their expenses will be automatically logged in the application without any additional effort on their part.
TLS
Introduction
This implementation of the TLS protocol is meant for learning purposes.
Stage 1
Table of Contents
Brief
At stage 1, this project implemented the server end of TLS1.2 with C++20. However, the build up of shit code made it nearly impossible to continue after successfully establishing the first TLS connection and deciphering the very first application data. As a result, the project was re-started.
TLS version 1.2
In the inital Client Hello handshake message, the client will specifiy all supported cipher suites and public crytographic parameters, it also includes a 32 bytes of random data and a sequence of bytes for session ID. The random bytes would be used later in shared-key derivation.
The server will respond with a Server Hello message, it also contains 32 random bytes and session ID, but it would choose one cipher suite and the required public crytographic parameters. The server would also send a Certificate signed by a CA to the client. The certificate contains a public key for the clients to encrypt a pre-master secret. Only the server is capable of decrypting the pre-master secret due to the properties of asymetric encryption, and the certificate is signed with the private key of the CA, which nobody acknowledges, so by using the public key of the CA, held by the operating systems, it is sufficient to assure that the public key contained inside the certificate has not been modified by any attackers in the network. On top of that, since only the server has the private key, nobody else except the client and the server knows the pre-master secret.
The pre-master secret itself is not long enough to be directly used as session keys, and to avoid bad implementation of TLS that use the same pre-master secret repeatedly, the pre-master secret with be extended to obtain the master secret using the random bytes sent. If the extended-master secret extension was specified in the client hello and server hello messages, all handshake message would also be included to add an additional level of security.
After key negotiation, both the server and client will send a Change Cipher Spec handshake message to indicate that all messages beyond would be encrypted with the session key. At the end of the handshake, it is required to send a hash of all messages encrypted with the new session key to ensure that the handshake messages are not modified by attackers and to ensure that there are no errors in key calculation of both sides.
Features
There is limited amount of features and support, and the cipher suites supported are not the most secure; in fact, it only supports RSA key exchange and AES in GCM mode for stream cipher using SHA2 as the hashing algorithm.
Learn
- wireshark
- openssl
Demonstration
It is able establish a TLS connection with the client (Google Chrome browser).
- Clients initiate request (with TLS parameters)
- Server sends the parameters with a self-signed certificate to the client (daimaoguai.com, I did not registered this domain)
- Client encrypts pre-master secret with the public key and sends it back to server
- Server and client both produces the same master secret and produces the key block from it
- Sends Change Cipher Spec: all data after are encrypted
- Sends Finish: ensures both parties produced the same keys
- Server successfully decrypted the HTTP request.
*************************************
compiled at: Dec 30 2025, 19:30:17
start initiation
read certificate[1378]
setted signal handlers
starting HTTPS server
listening to port 443
*************************************
client hello[1774]
server hello[53]
server certificate[1388]
server hello done[4]
ALERT!
client hello[1742]
server hello[53]
server certificate[1388]
server hello done[4]
ALERT!
client hello[1806]
server hello[53]
server certificate[1388]
server hello done[4]
ALERT!
client hello[1742]
server hello[53]
server certificate[1388]
server hello done[4]
client key exchange[514]
client change cipher spec[1]
client finished[12]
server change cipher spec[6]
server finished[16]
TLS application data[709] at memory[0x0x7fca7500b09d]
GET / HTTP/1.1
Host: localhost
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: "Google Chrome";v="141", "Not?A_Brand";v="8", "Chromium";v="141"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9,en-CA;q=0.8,en;q=0.7
�~�C
_(�I�FY�t�V��G��
client hello[1774]
server hello[53]
server certificate[1388]
server hello done[4]
ALERT!
client hello[1742]
server hello[53]
server certificate[1388]
server hello done[4]
ALERT!
client hello[1774]
server hello[53]
server certificate[1388]
server hello done[4]
ALERT!
client hello[1774]
server hello[53]
server certificate[1388]
server hello done[4]
client key exchange[514]
client change cipher spec[1]
client finished[12]
server change cipher spec[6]
server finished[16]
TLS application data[709] at memory[0x0x7fca7480f0bd]
GET / HTTP/1.1
Host: localhost
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: "Google Chrome";v="141", "Not?A_Brand";v="8", "Chromium";v="141"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9,en-CA;q=0.8,en;q=0.7
���"�Ҙ
���ۮ�9f�
^C
*************************************
Signal captured[2]
Interrupt: 2
Keyboard Interruption
Terminating proccess...
freed all clients
successfully closed server end socket
Issues
The structure and style of code resulted in poor readability. The comprimises made during development that were supposed to be fixed have never been revisted. The extensive use of stack memory, pointers and casting for fast implementation made it difficult to follow. This bad habit resulted in extremely unsafe code for deployment; in fact, segmentation fault and stack buffer overflow occured several times. The documentation can be improved by specifying the side effects of the code. The structure of the implmentation is done well. Few functions and classes are responsible of long heavy tasks. Despite the improvement of documentation from previous projects, the style cannot keep up with the growing size of this project.
References
- RFC5246: The Transport Layer Security (TLS) Protocol Version 1.2
- SHA256 Algorithm
- RFC2104: HMAC: Keyed-Hashing for Message Authentication
- RFC5280: Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile
- RFC5116: An Interface and Algorithms for Authenticated Encryption
- RFC5288: AES Galois Counter Mode (GCM) Cipher Suites for TLS
- FIPS197: Advanced Encryption Standard (AES)
- NIST: Galois/Counter Mode (GCM) and GMAC
- The Galois/Counter Mode of Operation (GCM)
- NIST: Methods and Techniques
- GCM Examples
WiFi Controlled Robot
Concept
Remote controlled rescue and reconnaissance vehicle used in situations where people are unable to help. Programmed and controlled through Arduino, and contains various sensors for collecting data. The robot is controlled over the WiFi by a computer.
Applications
Rescue and reconnaissance are two of the future applications. There are many times when wired robots cannot be used in rescues and reconnaissance, because the wires would tangle up when moving around. It is very difficult and time-consuming to untangle them remotely, which wastes time in a rescue. Time is life.
Due to the limitations of Bluetooth, rescue and reconnaissance robots have a limited communication bandwidth. This limits the amount of sensors and equipment the robots can use, such as 360° camera, microphone, earthquake sensors, infrared temperature detection camera, etc... Not to mention the accelerating development of the internet and wireless internet communication. Wireless and high speed are the advantages of a network controlled robot that Bluetooth and wires cannot have and characteristics that make network controlled robots stand out. With that said, there are way more applications of this technology in the future than just simply a rescue and reconnaissance vehicle.
Table of Contents
- December 15th, 2021
- December 16th, 2021
- December 17th, 2021
- December 31th, 2021
- January 10th, 2022
- January 11th, 2022
- January 12th, 2022
- January 13th, 2022
- January 14th, 2022
- January 23th, 2022
- January 24th, 2023
- January 25th, 2022
Log #1 - December 15th, 2021
What was done
I downloaded and installed the libraries for the ESP8266, then I tested it with a simple LED blinking code.
Brainstorm/Reflection
The importance of device drivers are crucial. They are responsible for the communication between the operating system and the devices. It is impossible to use the full abilities of the devices without the help of the drivers. The basic drivers that UEFI loads during the DXE stage can help operating system to utilize most devices, but certainly not all, and definitely don’t push the devices to their full capabilities.
It is important to look at the specifications of the products when purchasing a cable, because some only have two wires inside for power delivery and no wires for data transmission.
Issues and Fixes
The Arduino IDE was not able to detect the USB port connecting to the ESP8266. So I searched for the driver online and installed it. It still didn’t work. I looked for clues on the internet, and an article suggests that it might be the cable that I was using was a power delivering cable, which is not able to transmit data. So I replaced that cable with another one. The Arduino IDE was able to detect the port and upload the code.
Accomplishments and Next Steps
I tested the ESP8266 with a simple LED blinking code. Next step is to connect it to the Wi-Fi.
Log #2 - December 16th, 2021
What was done
I researched about Wi-Fi connections on ESP8266, looked at documentation of the ESP8266 from the official website of the manufacturer, and also found an Arduino library (ESP8266Wi-Fi) online. I wrote some code to connect it to my own Wi-Fi. It scans all the nearby available SSIDs and their signal strength.
Brainstorm/Reflection
Using Wi-Fi in this robot is a better choice than Bluetooth and wired-controlled. This conclusion stands because of multiple reasons. Firstly, Wi-Fi can provide faster communication between the robot and the controller, which allows more control of advanced sensors and rescue equipment that requires bandwidth. Secondly, using Wi-Fi allows the controller to control multiple robots at the same time which Bluetooth does not allow. Thirdly, the ability to connect to Wi-Fi means that the robot can be connected into the internet, which allows distant controls of the robots, unlike Bluetooth which would have a significant latency to convert the Bluetooth data. Even Though wired robots also have the advantages listed above, the data transmission wires of wired robots might tangle up, which has no benefits in a rescue. On the other hand, Bluetooth’s low power consumption is one of its advantages, but the rescue robot is big enough to fit a battery inside. In addition, the ESP8266 can turn off the antenna (the different sleep modes) to save battery.
Issues and Fixes
No issues today.
Accomplishments and Next Steps
I tested the ESP8266 by scanning nearby Wi-Fi routers and connecting it to my Wi-Fi. Next step is to make a connection to my computer.
Log #3 - December 17th, 2021
What was done
I researched about creating a TCP connection using the ESP8266Wi-Fi library, and wrote some code for the arduino to establish a TCP connection. I wrote some C code on my computer to establish a TCP connection with the robot using sockets.
Brainstorm/Reflection
The reason that I chose TCP instead of UDP connection is that I need the commands and data to be transferred in order, and ensure that my commands from the controller (computer) are received by the robot. This is a great advantage in rescue, because oftentimes, the robot is not in sight of the controller, which means that the controller would have a difficult time figuring out which commands are executed or not.
If I am able (if I have time) to put a camera on the robot, I would use a UDP connection for the video data instead. The reasoning behind this is that it is more about speed and latency than the smoothness of the images when it comes to live video connections. If a frame is lost during transmission, simply ignore it. Rescue teams need the newest images instead of the old ones.
Issues and Fixes
No issues today.
Accomplishments and Next Steps
I connected the ESP8266 to my computer through a TCP connection. Next step is to control it with my computer.
Log #4 - December 31th, 2021
What was done
I configured my VS Code for Arduino. I wrote a lot of code for the communication between the controller and the robot. I tested the communication and execution of commands. Then, I had made huge amounts of changes to the code for better communication supporting commands, messages, data etc…
During the winter break, Henry had typed out the documentation for the summative assignment. In the six hundred words documentation, he briefly mentioned the history of the technology, current and future applications and technology, as well as the possible improvements.
Brainstorm/Reflection
The choice of IDE is important in a project, especially in a large project. The coder (me) had to spend most of my time with the IDE to code. An efficient IDE would save a lot of time and energy. The Arduino IDE had a very limited amount of functionalities compared to VS Code. I found it annoying scrolling through the code that I didn’t want to look at. However, with VS Code, it shows the declarations when the mouse hovers over it and jumps to the line of code I wanted to see with a single click.
Issues and Fixes
It was not able to send messages and data. To solve this problem, the controller has to send an extra byte stating the type (command, message or data) of the data before sending the actual data.
There was a problem with sending messages between the robot and the controller. When the robot or the controller receives a message, it doesn’t know the length of the message/data. To solve this problem, two extra bytes of data have to be sent before the actual data is being sent to tell the receiver the length of the message. So the receiver would not receive the next command or data that is not relevant to the data that the receiver is handling.
Accomplishments and Next Steps
The robot is able to receive commands from the controller and execute them.
Log #5 - January 10th, 2022
What was done
I added a lot of code to handle errors for the controller, including the return of status from the robot, and the error handling when setting up the controller. It is much easier to debug.
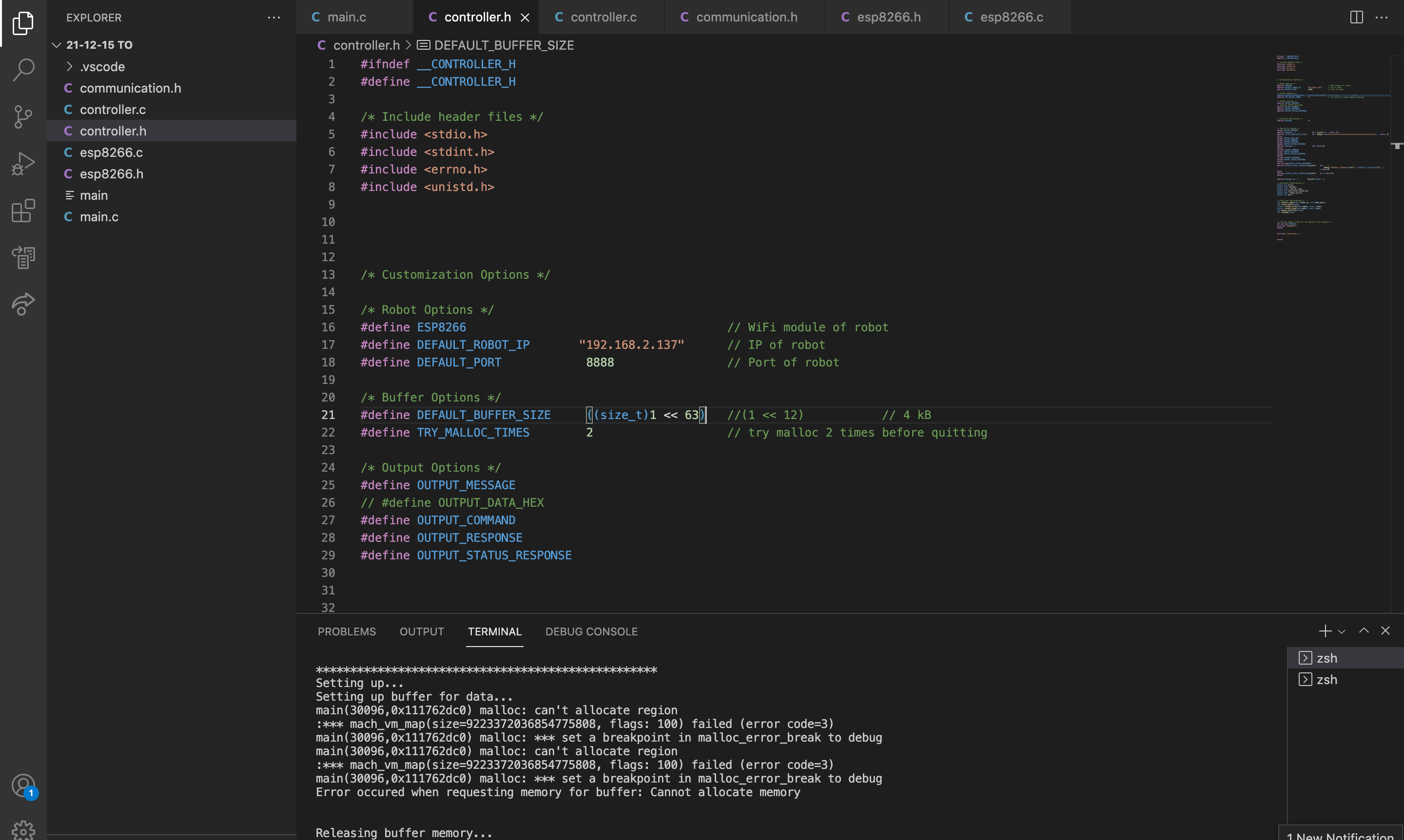
Brainstorm/Reflection
Error handling is a big part of this rescue robot. If an error occurs during rescue, there is not much time for engineers to find out what happened and fix the problem. The robot has to tell the controller everything about its status.
Issues and Fixes
There was a bug in the error handling code. I later found out that it was because a big bracket was missing in the code, but the indentation was correct. It took quite a while to find that bug.
Accomplishments and Next Steps
It is able to handle errors.
Log #6 - January 11th, 2022
What was done
When I tried to work on the ESP8266, one of the diodes for supplying power was killed from high voltage (9 volts). I measured it with a multimeter. The voltage across the diode was low (around 1 volt). I try to remove the diode and replace it with a piece of copper wire, but it is too small to work with. Luckily, the ESP8266 can still run with battery, and I have done most of the coding for it.
Brainstorm/Reflection
Voltage protection is one of the most important parts of modern day computers. It is there to protect circuits and electrical components from damage. I remember when I was little, computers were more fragile. There are many grounding and temperature protections. That was the only classroom with air conditioning.
Issues and Fixes
One of the diodes on the ESP12e development kit was damaged. I was not able to fix it.
Accomplishments and Next Steps
I killed one of the diodes.
Log #7 - January 12th, 2022
What was done
I found out that my router was assigned with a public IP address, which allows me to connect to it from the internet with port forwarding. I looked up the public IP address and configured port forwarding on my modem. I asked Henry to request the IP address and the specific port on his browser. The ESP8266 was able to receive the requests, even though it cannot decode nor parse the requests.
Brainstorm/Reflection
There is not enough IPv4 address for every device on Earth. Engineers came up with two solutions, one of them is IPv6, and the other is Network Address Translation (NAT). NAT is based on IPv4, not all devices are assigned with a public IP address. NAT translates the private IP address into a public IP address that is being shared with other devices. There are a lot of changes and time needed to transition to IPv6, but since NAT is based on IPv4, it takes less time and money to use NAT than IPv6.
One of the drawbacks of NAT is that it doesn’t allow a device to access another device with a private IP address though the internet. Address translation happens at the modem, which I have access to. I can set up port forwarding on my modem, so when a device tries to access the specified port of the modem, the request would be forwarded to ESP8266.
It is lucky to have NAT instead of a double NAT. In a double NAT situation, I have to set up port forwarding in routers where NAT happens, but I do not have access to all the routers. In that case, Henry would not be able to access my ESP8266.
Issues and Fixes
No issues today.
Accomplishments and Next Steps
It is able to connect to the internet.
Log #8 - January 13th, 2022
What was done
I realized that I had made a big mistake in using the C language. I should have used other programming languages instead for cross-platform compatibility. So I read the documentation of Microsoft about creating sockets on Windows, and tried to write some code.
Brainstorm/Reflection
Compatibility and portability are important. It saves a lot of time rewriting code just to run the same functionality on another computer.
Issues and Fixes
I wrote my code on macOS, which means that the code cannot compile on the Windows platform. I tried to learn about coding Windows programs and actually write some code for it.
Accomplishments and Next Steps
Learned a bit about Windows.
Log #9 - January 14th, 2022
What was done
I wrote more code for turning the motors using the motor driver on the ESP8266 development kit and tested it. It is able to go in a straight line. I also wrote code for the ultrasonic sensor.
Brainstorm/Reflection
The reason that the robot was not able to move forward in a straight line is that the motors were spinning at different speeds, even though the PWM signals used to control the L293D chip were identical. There are many factors contributing to this issue. The major factor is the errors during manufacturing. The motors and wheels are not manufactured perfectly, resulting in this issue of the robot.
Issues and Fixes
The ultrasonic sensor kept returning weird values, later found out that it was because of a wrong value in the code.
Accomplishments and Next Steps
The robot is able to go in a straight line and detect distances with the ultrasonic sensor.
Log #10 - January 23rd, 2022
What was done
I had rewrote the code for it to run on Windows operating system, and tested it on a virtual machine. I tested the wheels of the robot, and recorded data to find out the relationship between runtimes and distances, and constructed a function for the robot to travel a specific distance with the data collected.

Brainstorm/Reflection
I measured the diameter of the wheel and used that to derive a function for computing the time needed. However, because of the various errors including manufacturing errors, I still have to fine tune the code and values, which would take a lot of time.
Issues and Fixes
The code was not able to read a file, later found out that it is because of a ‘+’ that should not be there.
Accomplishments and Next Steps
The robot is able to go to a specific location.
Log #11 - January 24th, 2023
What was done
I ran the program on a computer from a different network, the robot is controlled with commands.
Brainstorm/Reflection
Issues and Fixes
Accomplishments and Next Steps
Simple testing for long range.
Log #12 - January 25th, 2022
What was done
I did some optimizing to the code to improve both readability and performance, and tested it.
Brainstorm/Reflection
Oftentimes, the use of switch statements is a better choice than if-else statements. In terms of readability, switch statements give a sense of matching, which is exactly what is needed in most scenarios. Switch statements would create a table-like structure to store the addresses of jumps. This way it can jump directly to the right address and execute code faster. It has two advantages, firstly, switch statements do not evaluate all predicates, and secondly, CPU instruction pipelines will not be disturbed multiple times due to branch prediction failures.
Issues and Fixes
The program stopped when reading the help menu file. I later found out that the default buffer size was too small, so I fixed it, and the problem disappeared.
Accomplishments and Next Steps
I did some optimizing of the code. Next step is to compile it into an executable file.
Table of Contents
Documentation
Many of the videos and images of the project were lost and cannot be documented in the engineering log.
Firewall
Under certain networks, the connection might be identified as a threat by the firewall and be terminated the connection between the client and the robot. This problem occured when testing under the TDSB (Toronto District School Board) network.
Code
Style
The code is not properly formated and documented for readibility. It is filled with long functions with heavily nested if-else statements, and the control flow is not clear.
Robustness
The error handling only does not cover all possible exceptions.
Testing
There are neither function tests nor unit tests. All tests performed were done by executing the compiled program.
Compatibility
There were issues with cross-platform compatibility, the Win32 API is different from the API for UNIX like operating systems, and code had to be re-written for the same functionality on a different operating system.
racketx
Link to repository: https://github.com/jianxun-p/racketx
Brief
This project is a meant for learning purpose. After taking the course CS135, which I learned Racket, I was inspired by the concepts of functional programming and the essentials of Racket, so I started this project that allows me to write Racket code in Rust.
Macros
Macros and meta programming are considered one of the significant part of the Rust programming language, it avoids many repetitions of code and embeds Domain Specific Languages. I started off with using macro_rules, which provided extensive pattern matching capabilities, but it was not enough for this complicated task. As a solution, I turned towards using proc_macro. It was very powerful, yet, it consumes surprisingly more time to compile.
Example
Here is an example of using the racket macro.
extern crate racketx; use racketx::racket; pub fn main() { racket!{ (define add_2_num (lambda (x y) (+ x y))) (define result (add_2_num 239 (- 9))) }; assert_eq!(result, 230); }
Features
- definition of constants
- lambda
- integer operations (+, -, *, /)
-
negative integer (alternate solution: express with subtraction, e.g.
-8would be(- 8)) - non-integer
- conditional statements
- lists
- function definitions (alternate solution: use constants definition with lambda)
- modulo arithmetic
HTTP Proxy
Table of Contents
Introduction
This project is meant to learn and understand how the internet works. This simple HTTP proxy server forwards all client requests to the targeted server, and provide an additional layer of security for the users.
Objectives
On a HTTP request to the server, the client establishes a TCP connection with the server. However, in order to do so, both client and server have to know the TCP port number of the other side. Similarly, to establish a TCP connection, IP packets containing information of the IP address of both end will be sent between them. Both connection ends will know the IP address and TCP port of the other end.
This can be a problem for the client. The location of the device can be easily figured out using IP lookups, and the server may respond differently based on the region/area of the client. For example, the same product on the same website might offer a different price for customers in Canada in comparison with the ones in Russia. Which is against the will of customers for goods of lower prices.
By hiding the IP address and TCP port information of the client from the server, proxy servers provides an additional level of anonymity to the clients.
Principles
Request
The initial request from client would be parsed to obtain the designated address or domain name, and the proxy server would establish a TCP connection with the given host. Immediately after this, the proxy server would modify the request and send it to the service provider.
URL
In a HTTP request from any client, a URL in absolute form is provided; however, the absolute form contains the domain name of the server, which often shows up in proxies connections. However, the goal is to prevent the server's acknowledgement of the proxy, so the proxy server would replace the entire URL with the requested path and the query string.
Proxy Parameters
The client would also include proxy parameters in the header of the request, such as Proxy-Connection or Cache-Control to configure the connection between the proxy and the client. However, this information does not need to be forwarded to the server, and hence, they are removed as well.
Error
The proxy server is required to handle some errors, such as an invalid address or domain that cannot be reached, or the client is requesting resources of the proxy server itself. These errors should be handled and returned to the client, then the connection would be terminated.
Additional Information
Click link for more information about HTTP Requests.
Response
All responses from the server would be blindly forwarded back to the client.
Implementation
Environment
Running on macOS, this project is implemented using the language and version of C98 with the standard C library, r. The compiler used is Apple clang version 15.0.0.
Client Connection
In the main function, a TCP listener would be created and binded to the given address. After initialization, the proxy server would accept incoming client connections using a while loop and call the handler function with the file descriptor of the TCP connection.
For all clients, their initial request would be parsed to obtain the designated host and the proxy parameters, then this information would be removed from the request. This step is done by if-else statements with the strstr function provided by the standard C library. This is not the best approach for large scale application as it would result in lengthy code and poor readability; however, this proxy server only looks for a limited amount of parameters while leaving others untouched, this approach is a much simpler method to implement.
The function would then create a TCP connection to the requested server parsed in the previous step. Immediately, the modified request would be sent to the designated server.
After the initial request, a while loop would continuously attempt to read from both ends with blocking. If a message is received from either ends, then the message would be blindly forwarded to the other end. In the scenario where any of the connection is closed or broken, the proxy would close both connection and the handler function would return.
Concurrency
In the case when a connection is maintained for a while, the thread would be blocked to wait for incoming messages of the existing connection, thus, no new clients can be accepted, and only one client can be serviced at a time.
To solve this problem, when TCP connection is accepted, a new thread would be created to run the handler function with the TCP file descriptor supplied. Each thread handles one client.
Issues
Documentation
There are no function documentations.
Code
Style
The code is not properly formatted and documented for readability. It is filled with long functions with heavily nested if-else statements, and the control flow is not clear.
The messages printed to standard inputs and error are not properly formatted. In addition, the error messages do not contain enough information and no stack trace of any sort is presented.
Few comments are presented.
Robustness
There is neither error handling nor bound checking for indexing. An array is statically allocated to store pthread_ts created, but the index used to record the number of threads created grows with bound checking. It would definitely cause an overflow when the total amount of clients exceeds the limit. There is also no maintaining functionality for the array to continuously check the status of the threads and removed them from array when the thread is joined. This made the problem worse. However, this is simple to implement, and this project is meant for learning, so there won't be a huge amount of requests.
Testing
There are neither function tests nor unit tests. All tests performed were done by executing the compiled program and sending requests with the Google Chrome.
Personalized Notes
Here is some of the additional notes of my own interpretation of the materials.
Statistics
Table of Contents
Combination, Permutation and Ordering
Multinomial Coefficient
In context of combinations, the number of ways to choose objects from a total of is given by . This is because the act of choosing is equvilant to categorizing or labeling the objects into 2 distinct categories, the chosen ones or the ones that is not chosen. There are ways to order objects. However, the order of both the chosen group and the non chosen group does not matter, and there are ways to order the chosen group, ways of ordering the non chosen group; hence, the number of ways to categorize the objects is .
Extending this concept, to partitioning the objects into categories, then if we need indistinguishable objects in the th category, then the number of ways to categorize is given by the multinomial coefficient .
Note: must be true.
Example
The number of distinct words that can be produced from the letters STATISTICS is , because the count of each letter is given by {S: 3, T: 3, A: 1, I: 2, C: 1}.
Permutation and Ordering
When the ordering is important, it is equivalent to categorizing objects into distinct categories, the category for the non-chosen objects and the categories with labels first, second, third, etc... Each category except for the non-chosen category contains exactly 1 object. Therefore, the number of ways to choose objects from is .
In other words, the act of ordering is fundamentally the same as giving unique labels.
Partition into Multiple Categories
The number of ways to partition indistinguishable objects into categories is given by
. To partition the objects into categories, we need sticks to seperate them. Hence, it requires spaces in total to place all objects and sticks. Out of those spots, of them would be for sticks and of them for objects.
To ensure that each category has at least object, the sticks have to be seperated by at least object (e.g. for , ). Then, we have to categorized (i.e. insert) the remaining objects, and by the result above, there are ways of doing so.
Note: Each category is distinguishable, so is different from .
The difference with the multinomial coefficient scenario is that this partition does not restrict the number of objects in each category, but both requires that every object is in one of the categories.
Examples
- Number of ways to give indistinguishable coconuts to distinguishable friends:
- Number of possible tallies of 20 indistinguishable votes to 6 distinguishable canidates:
Probability Distributions
Binomial and Multinomial Distribution
For Successes in bernoulli trials, there are ways of arranging the Successes and Failures. Therefore, the probability of successes is given by where is the probability of success in each bernoulli trial.
For experiments that have more than 2 possible outcomes in each trial, the multinomial coefficient would be useful.
Note: each trial is independent and the union of all outcomes requires to be the entire sample space.
Example
3 dices are rolled independently, find the probability of getting 2 six's and 1 five. The outcome of each trial is either 5, 6 or other, so the probability is: .
Alternatively, the only outcomes of the experiment that satisfy the conditions are , and we get the same result: .
Poisson Distribution
For any interval of space time, it can be uniformly partitioned into non overlapping sub-intervals (). Assume that each event is independent from each other. If an event occured in , then it is equally likely to occur in any of the sub-intervals. For each of the event that happened, the probability of it being in any of the sub-interval follows the discrete uniform distribution.
This is a different interpretation of the binomial distribution, this interpretation can be extended further to obtain the poisson distribution. As approaches , each sub-interval becomes a single moment in space time. The distribution of the probability of an occurance being at any of the moments is still uniform due to the property of independence; In fact, a continuous uniform distribution. The probability of occurances at a given moment, however, approaches 0.
If occurances are expected in the interval , then the probability of occurances actually takes place is .
Due to their similarity, the poisson distribution can be approximated with the binomial distribution when is large.
Product of Two Normal PDFs
Notation
- represents the PDF with , and
- represent the CDF of the standard normal distribution
Derivation
Consider and independently, and try to find .
Consider the exponent part and by completing the squares,
So,
, which yields the result of a scaled normal pdf with .
Product of Three Normal PDFs
For the case of , by using the above results, we get the result of a scaled normal pdf with a mean of , a variance of , and a scale factor of .
Filters
Consider altitude sensors on a rocket, their measurements often comes with some error in repsect to the real altitude. Assume that the error is normally distributed centered at 0, and the actual altitude of the rocket is uniformlly distributed for some values and .
Let be independent random variables for the predicted and measured values of the current altitude. For simplicity, only consider the bivariate case with and .
The purpose of sample filters are to filter out the error in measured and predicted value to give an best estimation of the actual value, in other words, find .
Bayes Filter
By Bayes Theorem, , and .
The denominator is an integral, . However, since is independent from , then
Since and are independent, then . By the results from the Product of Two Normal PDFs, . Therefore, , where and .
For the special case and , .
-Calculus
All mathematical objects can be described as a lambda expression, including numbers, data structures etc... It was also proven to be equivalently capable to Turing's machine.
Table of Contents
Syntax and Notation
In lambda calculus, the functions are defined to take only one argument, with a signifier indicating the start of a function definition, followed by a placeholder for the parameter with a '' symbol to separate the parameter with the return expression.
For examples is the identity function.
For any functions and parameters, an application of function to the parameter is denoted as . For multiple application of function, in lambda calculus is equivalent to in mathematics. One could use parenthesis to change the order of function application. would be equivalent to .
This does not provide the ability for multiple parameters, but it could be achieved with curing. For example, . A shorthand notation would be , but it is not a function with two parameters, but instead a function that takes in a function , and returns another function, which takes an argument and returns . The ordering does matter, and in this example, this lambda expression is different from .
-Reduction
The -reduction is a process of reducing a given lambda expression to the "-normal form" (the simplest form). Example:
Combinators
A combinator is a lambda expression that every variable is quantified. For examples, is a combinator while is not, because is not quantified in the second example.
Identity
is the identity, which maps all inputs to themselves.
Mockingbird
is the mockingbird combinator. It applies itself to itself. When is supplied to , can be reduced down to . However, would result in an infinite number of self application when reducing it.
Kestrel
always returns the first curried argument, so could be reduced to . It can be used as a constant, after applying an argument to it once, the result of a second application is not dependent on the second parameter. For example, is a function that always returns no matter the input.
Kite
always returns the second curried argument, so could be reduced to . By expanding this combinator, we obtain .
Cardinal
reverses the arguments of a function application. For example, can be reduced to .
Bluebird
is a combinator that allows composition of functions. It composes the function and .
Y Fixed-Point Combinator
This combinator is defined as , and it is equivalent to . By reducing this combinator we obtain:
and so on. This combinator's behavior is similar to a non-stopping recursion. With some modifications, it is equivalent to recursion in Turing machines.
Boolean
Logical operations can be performed with lambda calculus.
True and False
However, a definition for the logical true and false is required. Recall that everything in lambda calculus are functions, so the true and false can be defined as functions that take two arguments.
- True: returns the first argument (the combinator)
- False: returns the second argument (the combinator)
Negation
is the combinator for the logical not operation. When x is true, it would return which represents false. Otherwise, it would return which represents true. Notice that the cardinal combinator is exactly identical, which means that the cardinal is the combinator for boolean negation.
Conjunction
is the combinator for the logical and operation. Consider both cases of , this expression is also equivalent to
Disjunction
is the combinator for the logical or operation. Consider both cases of , this expression is also equivalent to
Data Structure
Data structure are used to hold data to be processed after, so the function would be given and applied after the data is stored. It would hold the data until is given, which will then return the value of the processed data.
For example, let the data structure be , this structure stores a pair of values. If we store the value true and false, we obtain . At this point, is a function that takes in an argument and returns , so applying the logical or operator would give , while supplying the logical or and operator yields .
Since everything in lambda calculus is expressed in functions, there is no data types, so the same combinator can be used for different types of data.
Church Numeral
Everything in lambda calculus are functions, so the natural numbers can be defined as functions that has two arguments:
- a function
- an argument that will be supplied to
In lambda calculus, a natural number are defined as a combinator that applied time on .
For examples:
Successor
A successor combinator is needed to allow the creation of any natural number by induction. It first applies times on , then an addition application. Notice that this is equivalent to .
Addition
Addition of numbers and can be defined as the succession of , or equivalently, the succession of .
Predecessor
In order to perform subtraction, we would need a combinator for the predecessor of the church numerals. Suppose there is a pair of values, where the second value is one greater than the first value, then the first value is the predecessor of the second.
Definitions:
as defined in Data Structure
returns the first value of a pair
returns the second value of a pair
is the pair
constructs a successor pair of the given pair.
Notice that when is applied times to the pair , the second value of the resultant pair would be , and since the first value is always the predecessor of the second, the first value would be for all . For . Hence, the predecessor combinator for all would be:
This definition of predecessor implies that the predecessor of 0 is 0 itself.
Subtraction
Subtraction of the natural numbers and can be defined as the predecessor of .
For , after or more application of on , the return value would always be 0.
Multiplication
Multiplication of natural numbers is repeated addition.
Power
Exponential of natural numbers is repeated multiplication.
Is Zero
When n is zero, there is no function application. Otherwise, the function , which is the constant function for false, would be called (perhaps repeatedly).
Ordering
This definition uses the property discussed in subtraction.
If and , then .
If , then .
If , then .
Cryptography
Algebra
Table of Contents
Number Theory
Euler's Totient Function and Modulo Multiplicative Group
Modulo Multiplicative Group: is the set of elements in that has a modular inverse under modulo .
Euler's Totient Function: (i.e. the number of elements in that has a modular inverse).
Multiplicative Order and Primitive Root and Index
Multiplicative Order: For any , the smallest positive integer that satisfies is the multiplicative order. Denoted as .
Primitive Root: Positive interger that satisfies . Primitive roots have the property .
Index (Discrete Logrithm): Exists an unique , such that and . It is bounded by .
Discrete Logrithm Problem: There does not exists an efficient alogrithm that can quickly compute the index.
Group
is a group consists of a non-empty set and a binary operation on any 2 elements of , with the following axioms being satisfied:
- Closed:
- Associative:
- Unique Identity:
- Unique Inverse:
Subgroup: is a subgroup of iff and forms a group.
Abelian Group: a group where is commutative for elements in (e.g., ).
Coset
For any ,
-
is the "left coset of in with the representative "
-
is the "right coset of in with the representative "
-
is the "coset of in with the representative " iff
Coset divides into subsets based on the relationship between elements in and any . All elements of belongs to some coset, so .
iff and have the same relative relationship with (i.e., ).
For example, let ,and , all elements in the congruence class (coset) all have the same relationship of .
Operation on Cosets:
Lagrange's Theorem: For any finite group with its subgroup , the cardinality of divides the cardinality of (i.e., ). Proof: All cosets in have the same cardinality as (the ordinary coset), since there exists a bijection mapping between any cosets and ; hence, .
Normal Subgroup: is a normal subgroup iff
Quotient Group: (e.g., )
Group Homomorphism and Isomorphism
Homomorphism: For groups , , if exists functions such that , then these two groups are said to be homomorphism.
Homomorphic Image: . Does not necessarily be the entire (i.e. may be non-surjective).
Homomorphic Kernal: , where is the identity in . Does not necessarily be (i.e. may be non-injective).
Isomorphism: Homomorphism but with the constrain that is bijective (i.e. exists). Denoted as .
Isomorphic groups are essentially the same group, and all properties are commonly shared.
Fundamental Homomorphism Theorem (FHT): For any homomorphism of group with a function , there always exists an isomorphism relationship, .
Cyclic Group
is a cyclic group with a generator of iff is a group (e.g., is a cyclic group).
Order of Element: For any group , , if is the minimum positive integer such that , then is the order of element . This is similar to the multiplicative order for .
- .
- If the order of a finite cyclic group , then the order of , and .
- Any order finite cyclic group, if , then there exists an unique subgroup with order .
- For any , the order of the element is .
- Cyclic group with order has distinct generators.
For integers , where is an odd prime and is a positive integer, there exists a primitive root . In addition, forms a finite cyclic group, so primitive roots are generators.
Ring
is a ring when:
- is an Abelian group
- is closed:
- is associative:
- Distributative law holds: and
Additionally, more restrictions can be placed:
- Ring with Identity: contains an multiplicative identity(i.e. )
- Commutative Ring: operation is commutative(i.e. )
- Division Ring: forms a group
Zero Element(): An element such that . This is also the additive identity (proof: ).
Identity(): The multiplicative identity. For any ring with , (proof by contradiction: ).
Zero Divisor: Non zero elements (), such that (e.g. ).
Integral Domain: a commutative ring with identity that there is no zero divisors and .
Characteristic
, where is the smallest positive integer such that . If such does not exists, then .
This is similar to the additive order of a given , except that the characteristic of a ring is for ALL .
Ideal
is a ring, for some , if
- is a subgroup of
- satisfies any of:
, then is called the "left ideal of " if (1) is satisfied, the "right ideal of " if (2) is satisfied, or simply "(two-sided) ideal of " if both conditions are met.
Principal Ideal
for some
If , then is the principal ideal of generated by .
Prime Ideal
If and , then is the prime ideal of (this is similar to in prime factorization).
Field
is a field when:
- is an Abelian group
- is an Abelian group
- Distributative law holds: and
All fields are integral domains, but only finite integral domains are fields.
Elliptic Curve Cryptography (ECC)
Table of Contents
- Elliptic Curve
- Elliptic Curve over Real Numbers
- Elliptic Curve over Finite Field
- Elliptic Curve in Cryptography
Elliptic Curve
Elliptic curves have the general form:
Weierstrass Form:
Montgomery Form:
Twisted Edwards Form:
All three forms are equivalent, as there exists bijective mapping of any curves between any two forms.
For any point in the general form , for some constants .
Elliptic Curve over Real Numbers
Denote the curve as .
For some constants , such that , the set of points on the curve is: , where is the identity (the point at infinity).
Point Addition
The sum of points and for elliptic curves is , where is the reflection over the x-axis of , and is the intersection point of line with the curve. If such point does not exists, then the sum would be the infinity point.
This operation is commutative, which means that the group is an Abelian Group, with the identity being .
Example with the curve , :
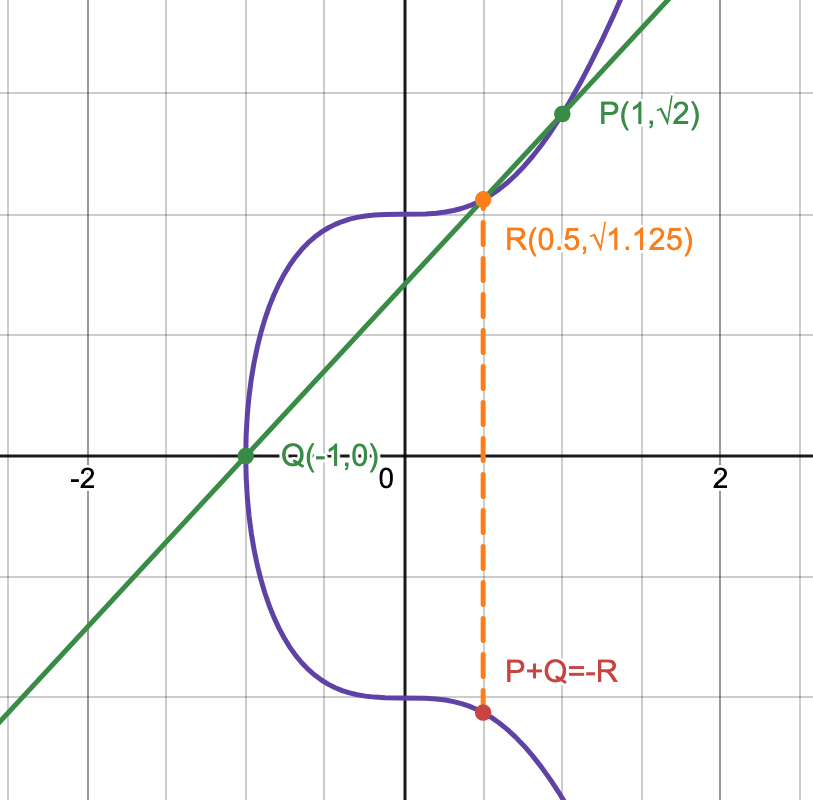
Algebraic Expression of Point Addition
Case
There exists only one intersection between the tangent line at and the curve; hence,
, and
.
Case
, where .
Case
would be the second intersection point of, the tangent line of the curve at . For curve in Weierstrass form, the formula is given as:
, where .
Case
, because there exists only one intersection between the tangent line at and the curve.
Point Multiplication
Point multiplication is defined to be repeated point addition. Given a point and an integer , . This could be done efficiently with the double-and-add method.
However, similar to the index, there is no more efficient method of finding given and in comparison with repeatedly subtracting from .
Elliptic Curve over Finite Field
For some prime and some constants , such that , the set of points on the curve is: , where is the identity (the point at infinity).
Point Arithmetic over Finite Field
Point addition over the finite field is similar to point addition over infinite field, with the exception that all operations are done under modulo , and division becomes multiplication with the modular inverse (always exists since the modulo is a prime).
Point multiplication over the finite field is repeated addition, and also can be computed efficiently with the double-and-add method.
Cyclic Group
To generate a cyclic group from , choose any point , and construct . This cyclic group of order would be a subgroup of . The order of depends on the choice of , and it must be a divisor of by Lagrange's Theorem.
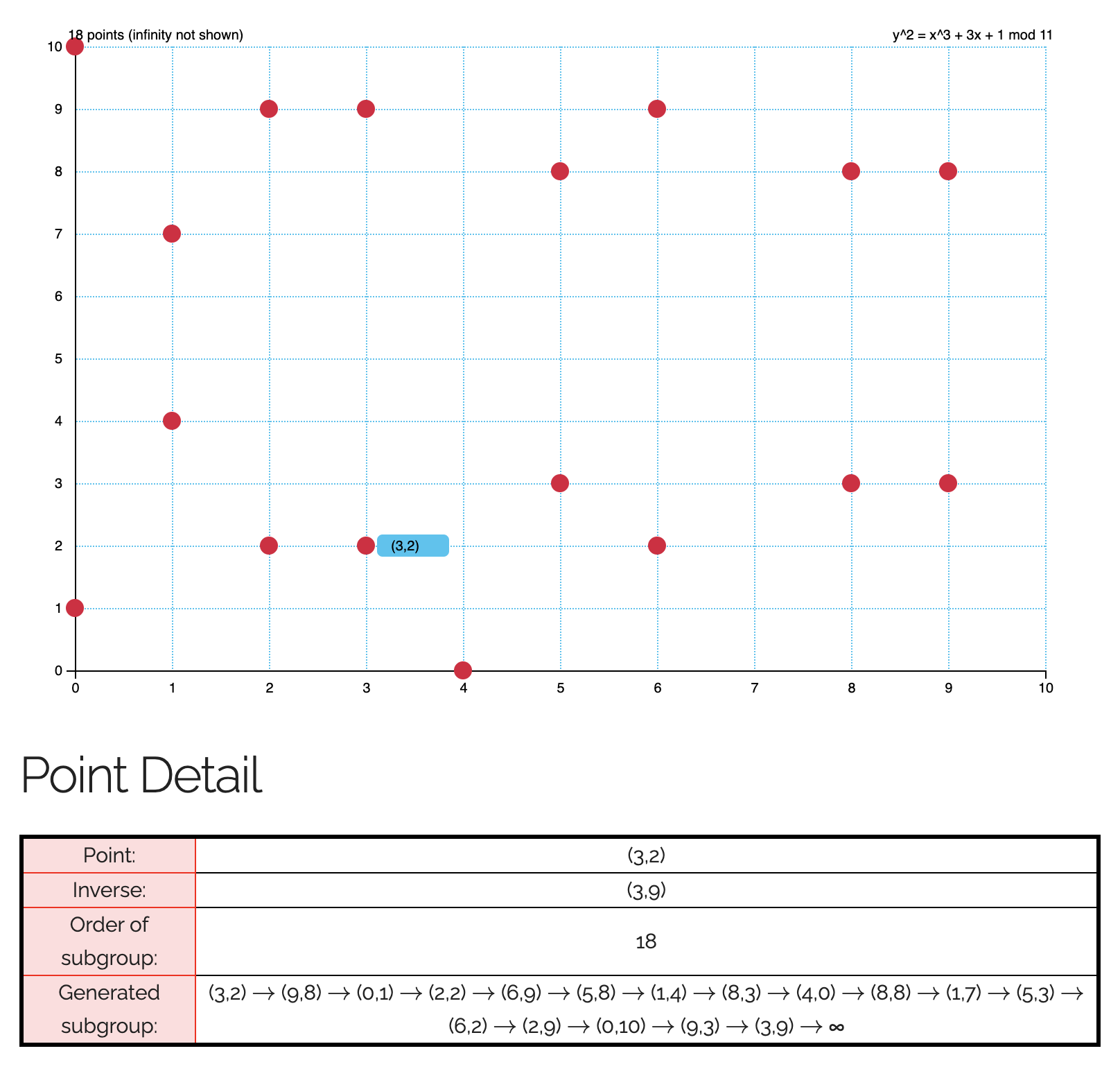 (An example of a cyclic group formed)
(An example of a cyclic group formed)
Elliptic Curve in Cryptography
ECC is based on elliptic curve over the prime finite field.